BiMDP¶
CodeSnippet
You can download all the code on this page from the code snippets directory
BiMDP defines a framework for more general flow sequences, involving
top-down processes (e.g. for error backpropagation) and loops. So
the bi in BiMDP primarily stands for bidirectional. It also adds
a couple of other features, like a standardized way to transport
additional data, and a HTML based flow inspection utility. Because BiMDP
is a rather large addition and changes a few things compared to
standard MDP it is not included in mdp but must be imported
separately as bimdp (BiMDP is included in the standard MDP
installation)
>>> import bimdp
Warning
BiMDP is a relatively new addition to MDP (it was added in MDP 2.6). Even though it already went through long testing and several refactoring rounds it is still not as mature and polished as the rest of MDP. The API of BiMDP should be stable now, we don’t expect any significant breakages in the future.
Here is a brief summary of the most important new features in BiMDP:
Nodes can specify other nodes as jump targets, where the execution or training will be continued. It is now possible to use loops or backpropagation, in contrast to the strictly linear execution of a normal MDP flow. This is enabled by the new
BiFlowclass. The newBiNodebase class adds anode_idstring attribute, which can be used to target a node.The complexities of arbitrary data flows are evenly split up between
BiNodeandBiFlow: Nodes specify their data and target using a standardized interface, which is then interpreted by the flow (somewhat like a very primitive domain specific language). The alternative approach would have been to use specialized flow classes or container nodes for each use case, which ultimately comes down to a design decision. Of course you can (and should) still take that route if for some reason BiMDP is not an adequate solution for your problem.In addition to the standard array data, nodes can transport more data in a message dictionary (these are really just standard Python dictionaries, so they are
dictinstances). The newBiNodebase class provides functionality to make this as convenient as possible.An interactive HTML-based inspection for flow training and execution is available. This allows you to step through your flow for debugging or add custom visualizations to analyze what is going on.
BiMDP supports and extends the
hinetand theparallelpackages from MDP. BiMDP in general is compatible with MDP, so you can use standard MDP nodes in aBiFlow. You can also useBiNodeinstances in a standard MDP flow, as long as you don’t use certain BiMDP features.
The structure of BiMDP closely follows that of MDP, so there are
submodules bimdp.nodes, bimdp.parallel, and bimdp.hinet. The
module bimdp.nodes contains BiNode versions of nearly all MDP nodes.
For example bimdp.nodes.PCABiNode is derived from both BiNode
and mdp.nodes.PCANode.
There are several examples available in the mdp-examples repository,
which demonstrate how BiMDP can be used. For example backpropagation
demonstrates how to implement a simple multilayer perceptron, using
backpropagation for learning. The example binetdbn is a
proof-of-concept implementation of a deep belief network. In addition
there are a couple of smaller examples in bimdp_examples.
Finally note that this tutorial is intended to serve as an introduction, covering all the basic aspects of BiMDP. For more detailed specifications have a look at the docstrings.
Targets, id’s and Messages¶
In a normal MDP node the return value of the execute method is
restricted to a single 2d array. A BiMDP BiNode on the other hand can
optionally return a tuple containing an additional message dictionary
and a target value. So in general the return value is a tuple (x, msg,
target), where x is a the usual 2d array. Alternatively a
BiNode is also allowed to return only the array x or a 2-tuple
(x, msg) (specifying no target value). Unless stated otherwise the
last entry in the tuple should not be None, but all the other values
are allowed to be None (so if you specify a target then msg can
be None, and even x can be None).
The msg message is a normal Python dictionary. You can use it to
transport any data that does not fit into the x 2d data array. Nodes
can take data from to the message and add data to it. The message is
propagated along with the x data. If a normal MDP node is contained
in a BiFlow then the message is simply passed around it. A
BiNode can freely decide how to interact with the message (see the
BiNode section for more information).
The target value is either a string or a number. The number is the
relative position of the target node in the flow, so a target value of 1
corresponds to the following node, while -1 is the previous node. The
BiNode base class also allows the specification of a node_id
string in the __init__ method. This string can then be used as a
target value.
The node_id string is also useful to access nodes in a BiFlow
instance. The standard MDP Flow class already implements
standard Python container methods, so flow[2] will return the third
node in the flow. BiFlow in addition enables you to use the
node_id to index nodes in the flow, just like for a dictionary. Here is
a simple example
>>> pca_node = bimdp.nodes.PCABiNode(node_id="pca")
>>> biflow = bimdp.BiFlow([pca_node])
>>> biflow["pca"]
PCABiNode(input_dim=None, output_dim=None, dtype=None, node_id="pca")
BiFlow¶
The BiFlow class mostly works in the same way as the normal Flow
class. We already mentioned several of the new features, like support
for targets, messages, and retrieving nodes based on their node_id.
Apart from that the only major difference is the way in which you can
provide additional arguments for nodes. For example the FDANode in
MDP requires class labels in addition to the data array (telling the
node to which class each data point belongs). In the Flow class the
additional training data (the class labels) is provided by the same
iterable as the data. In a BiFlow this is no longer allowed, since
this functionality is provided by the more general message mechanism. In
addition to the data_iterables keyword argument of train there
is a new msg_iterables argument, to provide iterables for the
message dictionary. The structure of the msg_iterables argument must
be the same as that of data_iterables, but instead of yielding
arrays it should yield dictionaries (containing the additional data
values with the corresponding keys). Here is an example
>>> samples = np.random.random((100,10))
>>> labels = np.arange(100)
>>> biflow = bimdp.BiFlow([mdp.nodes.PCANode(), bimdp.nodes.FDABiNode()])
>>> biflow.train([[samples],[samples]], msg_iterables=[None,[{"labels": labels}]])
The _train method of FDANode requires the labels argument, so
this is used as the key value. Note that we have to use the BiNode
version of FDANode, called FDABiNode (alomost every MDP node has
a BiNode version following this naming convention). The BiNode
class provides the cl value from the message to the _train
method.
In a normal Flow the additional arguments can only be given to the
node which is currently in training. This limitation does not apply to a
BiFlow, where the message can be accessed by all nodes (more on this
later). Message iterators can also be used during execution, via the
msg_iterable argument in BiFlow.execute. Of course messages can
be also returned by BiFlow.execute, so the return value always has
the form (y, msg) (where msg can be an empty dictionary). For example:
>>> biflow = bimdp.nodes.PCABiNode(output_dim=10) + bimdp.nodes.SFABiNode()
>>> x = np.random.random((100,20))
>>> biflow.train(x)
>>> y, msg = biflow.execute(x)
>>> msg
{}
>>> # include a message that is not used
>>> y, msg = biflow.execute(x, msg_iterable={"test": 1})
>>> msg
{'test': 1}
Note that BiNode overloads the plus operator to create a BiFlow.
If iterables are used for execution then the BiFlow not only
concatenates the y result arrays, but also tries to join the msg
dictionaries into a single one. Arrays in the msg will be
concatenated, for all other types the plus operator is used.
The train method of BiFlow also has an additional argument
called stop_messages, which can be used to provide message iterables
for stop_training. The execute method on the other hand has an
argument target_iterable, which can be used to specify the initial
target in the flow execution (if the iterable is just a single array
then of course the target_iterable should be just a single node_id).
BiNode¶
We now want to give an overview of the BiNode API, which is mostly an
extension of the Node API. First we take a look at the possible return
values of a BiNode and briefly explain their meaning:
executexor(x, msg)or(x, msg, target). Normal execution continues, directly jumping to the target if one is specified.
trainNoneterminates training.xor(x, msg)or(x, msg, target). Means that execution is continued and that this node will be reached again to terminate training. IfxisNoneand no target is specified then the remainingmsgis dropped (so it is not required to “clear” the message manually in_trainfor custom nodes to terminate training).
stop_trainingNonedoesn’t do anything, like the normal MDPstop_training.xor(x, msg)or(x, msg, target). Causes an execute like phase, which terminates when the end of the flow is reached or whenEXIT_TARGETis given as target value (just like during a normal execute phase,EXIT_TARGETis explained later).
Of course all these methods also accept messages. Compared to Node
methods they have a new msg argument. The target part on the
other hand is only used by the BiFlow.
As you can see from train, the training does not always stop when
the training node is reached. Instead it is possible to continue with
the execution to come back later. For example this is used in the
backpropagation example (in the MDP examples repository). There are also
the new stop_training result options that start an execute phase.
This can be used to propagate results from the node training or to
prepare nodes for their upcoming training.
Some of these new options might be confusing at first. However, you can simply ignore those that you don’t need and concentrate on the features that are useful for your current project. For example you could use messages without ever worrying about targets.
There are also two more additions to the BiNode API:
node_id- This is a read-only property, which returns the node id
(which is
Noneif it wasn’t specified). The__init__method of aBiNodegenerally accepts anode_idkeyword argument to set this value.
bi_reset- This method is called by the
BiFlowbefore and after training and execution (and after thestop_trainingexecution phase). You can be override the private_bi_resetmethod to reset internal state variables (_bi_resetis called bybi_reset).
Inspection¶
Using jumps and messages can result in complex data flows. Therefore
BiMDP offers some convenient inspection capabilities to help with
debugging and analyzing what is going on. This functionality is based on
the static HTML view from the mdp.hinet module. Instead of a static
view of the flow you get an animated slideshow of the flow training or
execution. An example is provided in
bimdp/test/demo_hinet_inspection.py. You can simply call
bimdp.show_execution(flow, data) instead of the normal
flow.execute(data). This will automatically perform the inspection
and open it in your webbrowser. Similar functionality is available for
training. Just call bimdp.show_execution(flow, data_iterables),
which will perform training as in flow.train(data_iterables). Have a
look at the docstrings to learn about additional options.
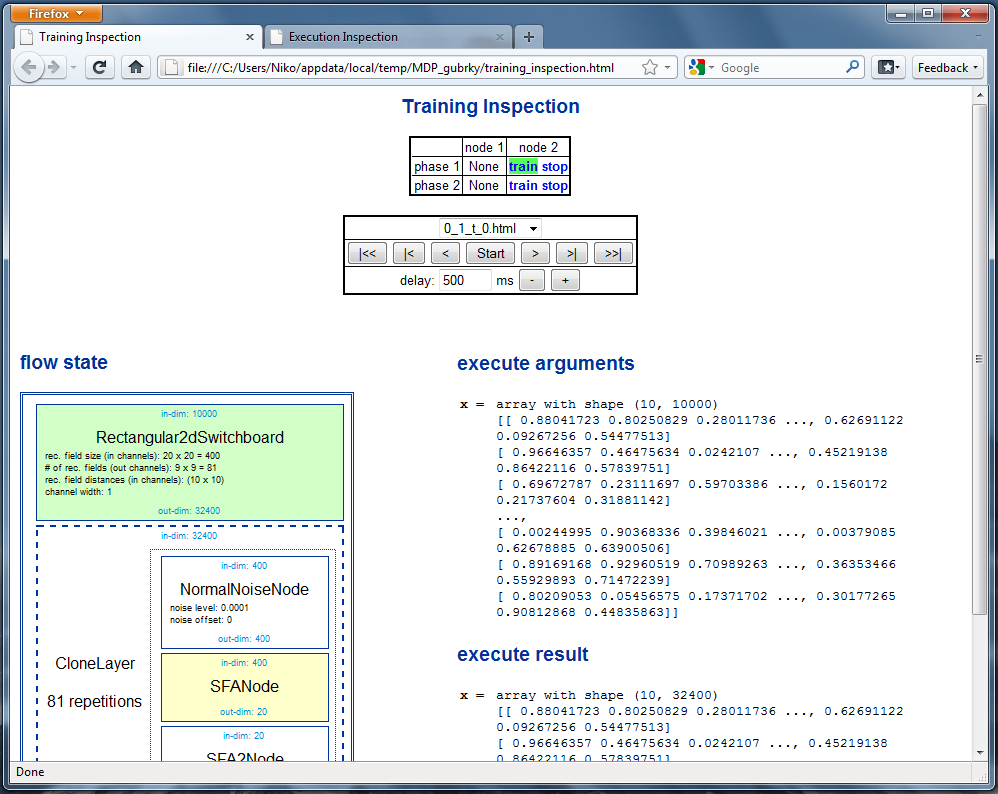
The BiMDP inspection is also useful to visualize the data processing
that is happening inside a flow. This is especially handy if you are
trying to build or understand new algorithms and want to know what is
going on. Therefore we made it very easy to customize the HTML views in
the inspection. One simple example is provided in
bimdp/test/demo_custom_inspection.py, where we use matplotlib to
plot the data and present it inside the HTML view. Note that
bimdp.show_training and bimdp.show_execution are just helper
functions. If you need more flexibility you can directly access the
machinery below (but this is rather messy and hardly ever needed).
Browser Compatibility
The inspection works with all browser except Chrome.
This is due to a controversial chromium issue. Until
this is fixed by the Chrome developers the only workarounds
are to either start Chrome with the --allow-file-access-from-files
flag or to access the inspection via a webserver.
Extending BiNode and Message Handling¶
As in the Node class any derived BiNode classes should not
directly overwrite the public execute or train methods but
instead the private versions with an underscore in front (for training
you can of course also overwrite _get_train_seq). In addition to the
dimensionality checks performed on x by the Node class this
enables a couple of message handling features.
The automatic message handling is a major feature in BiNode and
relies on the dynamic nature of Python. In the FDABiNode and
BiFlow example we have already seen how a value from the message is
automatically passed to the _train method, because the key of the
value is also the name of a keyword argument.
Public methods like execute in BiNode accept not only a data
array x, but also a message dictionary msg. When given a message
they perform introspection to determine the arguments for the
corresponding private methods (like _train). If there is a matching
key for an argument in the message then the value is provided as a
keyword argument. It remains in the dictionary and can therefore be used
by other nodes in the flow as well.
A private method like _train has the same return options as the
public train method, so one can for example return a tuple (x,
msg). The msg in the return value from _train is then used by
train to update the original msg. Thereby _train can
overwrite or add new values to the message. There are also some special
features (“magic”) to make handling messages more convenient:
- You can use message keys of the form
node_id->argument_keyto address parts of the message to a specific node. When the node with the corresponding id is reached then the value is not only provided as an argument, but the key is also deleted from the message. If theargument_keyis not an argument of the method then the whole key is simply erased. - If a private method like
_trainhas a keyword argument calledmsgthen the complete message is provided. The message from the return value replaces the original message in this case. For example this makes it possible to delete parts of the message (instead of just updating them with new values). - The key
"method"is treated in a special way. Instead of calling the standard private method like_train(or_execute, depending on the called public method) the"method"value will be used as the method name, with an underscore in front. For example the message{"method": "classify"}has the effect that a method_classifywill be called. Note that this feature can be combined with the extension mechanism, when methods are added at runtime. - The key
"target"is treated in a special way. If the called private method does not return a target value (e.g., if it just returnedx) then the"target"value is used as target return value (e.g, instead ofxthe return value ofexecutewould then have the formx, None, target). - If the key
"method"has the valueinversethen, as expected, the_inversemethod is called. However, additionally the checks frominverseare run on the data array. If_inversedoes not return a target value then the target -1 is returned. So with the message{"method": "inverse"}one can execute aBiFlowin inverse node (note that one also has to provide the last node in the flow as the initial target to the flow). - This is more of a
BiFlowfeature, but the target value specified inbimdp.EXIT_TARGET(currently set to"exit") causesBiFlowto terminate the execution and to return the last return value.
Of course all these features can be combined, or can be ignored when they are not needed.
HiNet in BiMDP¶
BiMDP is mostly compatible with the hierarchical networks introduced in
mdp.hinet. For the full BiMDP functionality it is of
required to use the BiMDP versions of the the building blocks.
The bimdp.hinet module provides a BiFlowNode class, which is
offers the same functionality as a FlowNode but with the added
capability of handling messages, targets, and all other BiMDP concepts.
There is also a new BiSwitchboard base class, which is able to deal
with messages. Arrays present in the message are mapped with the
switchboard routing if the second axis matches the switchboard dimension
(this works for both execute and inverse).
Finally there is a CloneBiLayer class, which is the BiMDP version of
the CloneLayer class in mdp.hinet. To support all the features
of BiMDP some significant functionality has been added to this class.
The most important new aspect is the use_copies property. If it is
set to True then multiple deep copies are used instead of just a
reference to the same node. This makes it possible to use internal
variables in a node that persist while the node is left and later
reentered. You can set this property as often as you like (note that
there is of course some overhead for the deep copying). You can also set
the use_copies property via the message mechanism by simply adding a
"use_copies" key with the required boolean value. The CloneBiLayer
class also looks for this key in outgoing messages (so it can be send
by nodes inside the layer). A CloneBiLayer can also split arrays in the
message to feed them to the nodes (see the doctring for more details).
CloneBiLayer is compatible with the target mechanism (e.g. if the
CloneBiLayer contains a BiFlowNode you can target an internal node).
Parallel in BiMDP¶
The parallelisation capabilites introduced in mdp.parallel can be
used for BiMDP. The bimdp.parallel module provides a
ParallelBiFlow class which can be used like the normal
ParallelFlow. No changes to schedulers are required.
Note that a ParallelBiFlow uses a special callable class to handle
the message data. So if you want to use a custom callable you will have
to make a few modifications (compared to the standard callable class
used by ParallFlow).
Coroutine Decorator¶
For complex flow control (like in the DBN example) one might need a node
that keeps track of the current status in the execution. The standard
pattern for this is to implement a state machine, which would require
some boilerplate code. Python on the other hand supports so called
continuations via coroutines. A coroutine is very similar to a
generator function, but the yield statement can also return a value
(i.e., the coroutine is receiving a value). Coroutines might be
difficult to grasp, but they are well documented on the web. Most
importantly, coroutines can be a very elegant implementation of the
state machine pattern.
Using a couroutine in a BiNode to maintain a state would still require
some boilerplate code. Therefore BiMDP provides a special function
decorator to minimize the effort, making it extremely convenient to use
coroutines. This is demonstrated in the gradnewton and binetdbn
examples. For example decorating the _execute method can be done
like this:
>>> class SimpleCoroutineNode(bimdp.nodes.IdentityBiNode):
... # the arg ["b"] means that that the signature will be (x, b)
... @bimdp.binode_coroutine(["b"])
... def _execute(self, x, n_iterations):
... """Gather all the incomming b and return them finally."""
... bs = []
... for _ in range(n_iterations):
... x, b = yield x
... bs.append(b)
... raise StopIteration(x, {"all the b": bs})
>>> n_iterations = 3
>>> x = np.random.random((1,1))
>>> node = SimpleCoroutineNode()
>>> # during the first call the decorator creates the actual coroutine
>>> x, msg = node.execute(x, {"n_iterations": n_iterations})
>>> # the following calls go to the yield statement,
>>> # finally the bs are returned
>>> for i in range(n_iterations-1):
... x, msg = node.execute(x, {"b": i})
>>> x, msg = node.execute(x, {"b": n_iterations-1})
You can find the complete runable code in the bimdp_simple_coroutine.py
example.
Classifiers in BiMDP¶
BiMDP introduces a special BiClassifier base class for the new
Classifier nodes in MDP. This makes it possible to fully use
classifiers in a normal BiFlow. Just like for normal nodes
the BiMDP versions of the classifier are available in bimdp.nodes
(the SVM classifiers are currently not available by default, but it is
possible to manually derive a BiClassifier version of them).
The BiClassifier class makes it possible to provide the training
labels via the message mechanism (simply store the labels with a
"labels" key in the msg dict). It is also possible to transport
the classification results in the outgoing message. The _execute method of a
BiClassifier has three keyword arguments called return_labels,
return_ranks, and return_probs. These can be set via the message
mechanism. If for example return_labels is set to True then
execute will call the label method from the classifier node and
store the result in the outgoing message (under the key "labels"). The
return_labels argument (and the other two) can also be set to a
string value, which is then used as a prefix for the "labels" key in
the outgoing message (e.g., to target this information at a specific
node in the flow).